

|
Getting your Trinity Audio player ready...
|
As the world delves deeper into the transformative realm of generative AI, the utilization of language model-powered chatbots and transition models is rapidly expanding. This surge of interest has prompted a widespread desire to understand the underlying technology fueling this disruption. In this blog, we will delve into the intricacies of this technology and provide a comprehensive, step-by-step guide on how to train your very own language model.
Introduction to LLMs
Language models have a history that traces back to Claude Shannon, who established information theory in 1948 through his influential work titled “A Mathematical Theory of Communication." The initial emergence of large language models occurred during the late 2000s and early 2010s, exemplified by noteworthy models like Google’s N-gram model and Microsoft’s Web N-gram model. These models enabled computers to generate natural language text by leveraging extensive linguistic data.
With time Language models (LLMs) have become indispensable for various applications, including search engines, chatbots, and virtual assistants. The recent advancements in this field have gained widespread recognition. Let’s explore some of the advantages offered by language models that aid organizations and individuals in achieving accuracy, efficiency, and scalability when generating natural text or synthetic data.
- Machine translation: Language models facilitate the translation of text from one language to another. By predicting the next word in the target language based on the words in the source language, accurate translations can be generated.
- Speech recognition: Language models contribute to speech recognition tasks. By predicting the next word in a sentence based on the audio signal, accurate speech recognition can be achieved.
- Text generation: Language models excel at generating text. By predicting the next word in a sentence based on the preceding words, coherent and contextually relevant text can be produced.
- Question answering: Language models can provide answers to questions. By predicting the answer based on the question and the surrounding text, effective question-answering systems can be created.
The potential applications are limitless and can greatly enhance processes and product operations.
step-by-step guide on how to build a LLMs
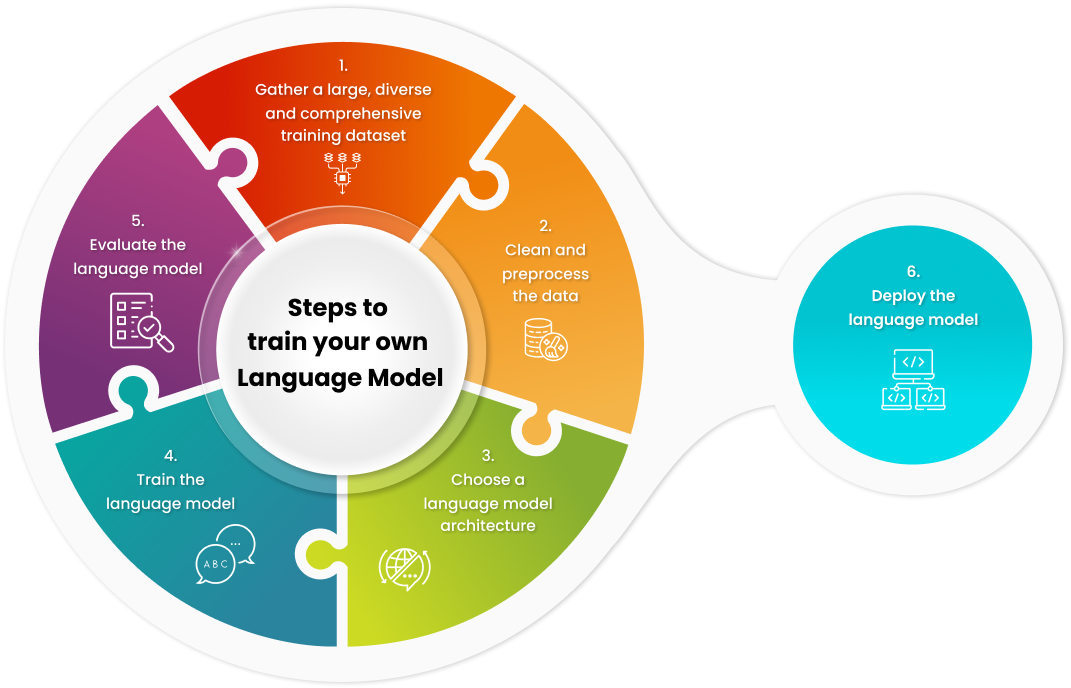
1. Gather a large, diverse, and comprehensive training dataset.
The first step to building an AI language model is to collect a dataset of text documents that you will use to train the model. This dataset should represent the language and domain that the model will be used for. You can follow different approaches to collect data and build a comprehensive dataset. Some of these approaches are:
- Public datasets: There are many public and openly available datasets that you can use to build your dataset, for example, the Common Crawl, the Wikipedia corpus, and the Gutenberg project datasets.
- Crawling the web: You can also crawl the web to collect text data. This can be a good option if you need to collect data on a specific topic or domain.
- Manually collecting data: You can also manually collect data by reading books, articles, and other text documents. This is a good option if you need to collect data on a specific topic or domain that is not available in public datasets.
Note: The larger and more diverse the dataset, the better the model will be able to learn.
2. Clean and preprocess the data.
Once you have collected your dataset, you need to clean and preprocess it. This involves removing noise, correcting errors, and transforming the data into a format that can be used by the language model. Some of the steps involved in cleaning and preprocessing data include:
- Removing noise: This involves removing text that is not relevant to the task at hand, such as headers, footers, and advertisements.
- Correcting errors: This involves correcting spelling and grammatical errors.
- Transforming the data: This involves converting the data into a format that can be used by the language model, such as a sequence of tokens.
Note: Clean and preprocess the data carefully to ensure that the model learns from the data correctly.
3. Choose a language model architecture.
There are many different language model architectures that you can choose from. Some of the most popular architectures include:
- Seq2Seq: This is a simple language model architecture that predicts the next word in a sequence.
- Transformer: This is a more complex language model architecture that uses attention to learn long-range dependencies between words.
- GPT-3: This is a large language model architecture that has been trained on a massive dataset of text.
Note: Choose a language model architecture that is appropriate for your application. There are many different architectures available, and it can be overwhelming to choose the perfect model architecture, so you need to choose one that is well-suited to the task you are trying to accomplish.
4. Train the language model.
Once you have chosen a language model architecture, you need to train the model. This involves feeding the model the training data and letting it learn the patterns in the data. The training process can take a long time, depending on the size of the dataset and the complexity of the language model architecture.
There are two main styles of language models: statistical language models and neural language models. Statistical language models are trained based on the idea that the probability of a word occurring in a sentence is influenced by the words that come before it. Neural language models, on the other hand, are trained based on the idea that the probability of a word occurring in a sentence is influenced by the entire sentence.
Statistical language models are typically trained on a large corpus of text, and they are used for a variety of tasks, such as machine translation, speech recognition, and text generation. Neural language models are typically trained on a smaller corpus of text, but they are more accurate than statistical language models.
Note: Train the model for a long enough time. Shorter training periods may affect the model’s accuracy and precision. It is vital to ensure that the model learns from the data as much as possible.
5. Evaluate the language model.
Once the language model has been trained, you need to evaluate it. This involves testing the model on a held-out dataset and measuring its performance. Some of the metrics that you can use to evaluate a language model include:
- Accuracy: This is the percentage of times that the model correctly predicts the next word in a sequence.
- BLEU score: This is a metric that measures the similarity between the model’s output and the ground truth.
- ROUGE score: This is a metric that measures the overlap between the model’s output and the ground truth.
6. Deploy the language model.
Once you are satisfied with the performance of the language model, you can deploy it. This involves making the model available to users so that they can use it. Some of the ways that you can deploy a language model include:
- Integrating the model into an API: This allows users to access the model through a web service.
- Building a web application: This allows users to interact with the model through a graphical user interface.
- Embedding the model in a chatbot: This allows users to interact with the model through natural language.
Building a language model for generative AI is a challenging but worthwhile endeavor. By following the steps outlined above, you can create a model that can generate text, translate languages, write different creative content, and answer your questions in an informative way.
If you’re eager to explore additional resources and expand your knowledge about Language Models (LLMs), the team at Soulpage is here to assist you. We are dedicated to providing valuable insights and guidance on LLMs. We provide comprehensive resources and extensive support so you can build your own LLMs model successfully. Don’t hesitate to reach out to us for further assistance and to enhance your understanding of this fascinating technology. Contact us today!
1 Comment
the information was really good